Can large language models (LLMs) and artificial intelligence (AI) unlock the secrets hidden within historical documents, such as showpeople periodicals? This question propelled researchers from the universities of Antwerp, Luxembourg, and Marburg to explore the potential of LLM/AI in a one-day workshop.

On 12 March 2024, scholars from the University of Antwerp (ARIA), the University of Luxembourg (C2DH), and the University of Marburg (Institute for Media Studies) joined forces to conduct preliminary tests for an interdisciplinary research project. This international group of researchers aims to study the changing mobility patterns of itinerant showpeople in Europe over a century-long period with a focus on their professional and family networks, and their channels for information and knowledge circulation. With little known about the intricate dynamics of their nomadic lifestyle, the team seeks to uncover these hidden narratives from 1880 to 1980.
This collaborative effort builds on the success of previous and ongoing projects like SciFair (UAntwerp 2021-2026), Popular Culture Transnational – Europe in the Long 1960s (C2DH, phase II, 2022-2026), and Performative Configurations of the Art of Projection for the Popular Transfer of Knowledge (UMarburg, 2019-2022).
Central to this endeavour are itinerant showpeople periodicals; trade papers that offer invaluable insights into the lives and networks of showpeople. These journals were published by showpeople’s unions or specialized publishing companies. For example, the publisher KOMET in Pirmasens, Germany, has been printing Der Komet twice a month since 1883. This journal was also read outside Germany and contained information on life events, itinerant fair routes, calendars, trade listings, reports from associated trade fairs, and advertisements.
Similar journals emerged across Europe in the late 19th century and circulated in France, Belgium, Germany, The Netherlands, Italy, The United Kingdom, Switzerland, and Austria-Hungary (Andersen 2023). Throughout the mid- and late 20th century, new journals continued to emerge and are still used by showpeople to share personal and professional messages to this day.
Experimenting with scalable reading
By analysing a set of journals from various European countries, the team aims to leverage LLM/AI to scale up the analysis and reveal hidden connections within the vast corpus of historical texts. The researchers have identified 54 journals in different languages, presenting a significant volume for analysis. This necessitates scalable reading methods and presents an opportunity to assess the efficacy of large language models (LLM) and artificial intelligence (AI) in analysing the corpus efficiently.
The methodology of the project will follow an iterative process to refine and optimize research methods. This approach enables experimentation with various LLM and AI methods, adapting them to address specific research objectives and challenges related to studying itinerant show people and artists. To explore the potential of these methods for further research, the team conducted first tests with multilingual journal samples.
The testing samples included pages and documents that contained information relevant to the research, and some random material that was not yet analysed. While several other LLM solutions compete on the market, ChatGPT4.0 by OpenAI currently offers the most advanced functionalities with limited infrastructural costs. The strength of LLMs in general and ChatGPT4.0 in particular lies in their capacity to aggregate different terms and concepts across languages.
Deciphering new media technologies
Like in the case of photography and electricity decades earlier, showpeople were early adopters who played a significant role in introducing new media and popularizing certain technologies. However, identifying the presence and impact of new media at the fairground is a challenge that traditional keyword searches may not adequately address. By training LLMs to recognize time-specific vocabulary and multilingual texts, the researchers aim to overcome this obstacle and uncover previously unnoticed trends or media that existed only for a short time.
In their digitization assessment, the researchers selected an edition from Der Komet and processed it using Transkribus for transcription. This resulted in segmented pages with distinct article boundaries and a full transcription of the text. Subsequently, they evaluated ChatGPT 4.0’s capacity to identify references to new media on a single page of the Der Komet issue. Encouragingly, the initial findings indicated that ChatGPT 4.0 successfully detected advertisements in German for various services relevant to showpeople, including photography, organ manufacturing, wax models, embroidery, and caravan production.

In line with the research question of detecting historical media technologies, the prompt was very specific in its formulation and composition: It provided additional context (information about the target audience and the text languages) and also instructed the system to indicate where it could not identify any references.
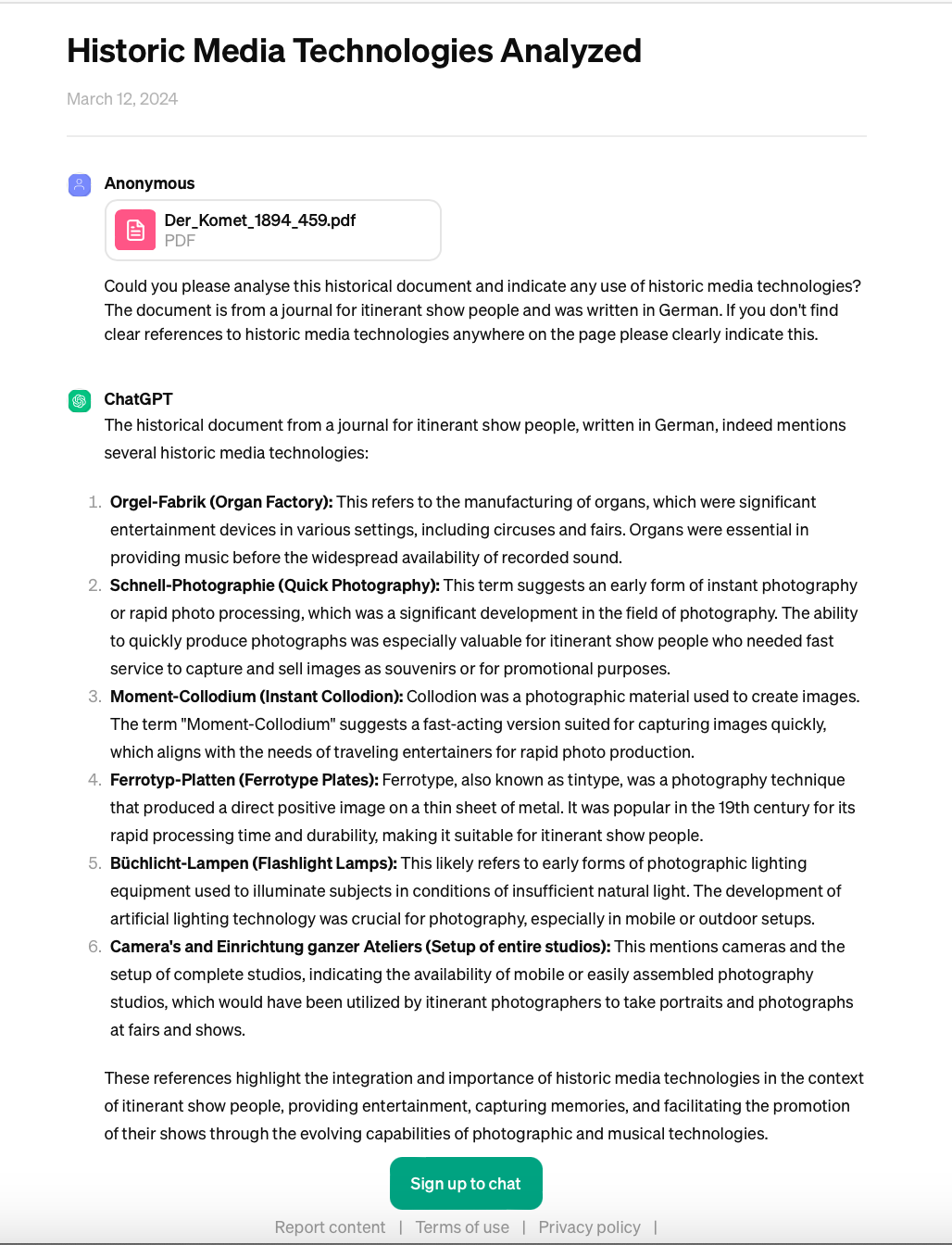
The extensive range of media technologies identified in the AI-generated response would typically be the result of meticulous and concentrated examination. This holds especially true for the subtly printed advertisement “Schnell-Photographie.” ChatGPT4.0 successfully identified various technologies and provided details on processes and historical context, including instant collodion, ferrotype plates, and flashlight lamps; all contextualized within the world of itinerant showpeople on fairgrounds.
These first experiments with ChatGPT4.0 by OpenAI have shown promising results, highlighting its ability to uncover new media and references within historical texts. In the context of multilingual texts and time-specific vocabulary, AI-generated responses proved to be very contextual, and a vector search using the presently established Retrieval Augmented Generation approach (RAG) exposed some interesting associations. The exploration of LLM and AI holds great promise for enriching historical research by leveraging vast amounts of data. In the context of fairground periodicals, it might unveil concealed dynamics and mechanisms concerning itinerant artists and showpeople.
However, to verify and enrich AI-generated responses, they will be cross-referenced with literature and other historical sources. Using LLM requires significant resources, and prompts should be “engineered” and employed strategically. Different prompting tactics can help to verify LLM results. If, for example, prompts include abstract or complicated concepts and ambiguous words, one can ask ChatGPT4.0 for its definitions and feed it new definitions if needed.
Some adjustments are needed to minimize errors introduced by document layout analysis (DLA) and optical character recognition (OCR). and Aautomating this task will enable efficient processing of extensive text datasets. Overall, this project represents a pioneering effort to unlock the potential of itinerant showpeople periodicals as a rich historical resource, shedding light on their contributions to European cultural history through the lens of large language models and artificial intelligence.
Disclaimer: The title of this blog post was suggested by ChatGPT3.5.